Algoritmi za traženje uzoraka
Algoritmi za traženje uzoraka
Kako bi se data miningom dani problemi rješavali što brže i točnije ,kreiran je niz algoritama:
Stablo odluka (engl. Decision tree)
Neuronske mreže (engl. Neural networks)
Kreiranje modela ponašanja klijenata i tržišta temelji se na prilagođavanju pojedinog algoritma pojedinom problemu. Algoritmu se kao ulaz daju određeni podaci, na temelju kojih on daje neko predviđanje. Ako je predviđanje koje daje algoritam u skladu s onim što se doista dogodilo, tada smo stvorili točan model. U suprotnom je algoritam potrebno korigirati. Kada smo upotrebom testnih podataka stvorili model, tada bi on trebao dati točna predviđanja za bilo koje podatke.
Pojedini algoritimi se razlikuju složenošću i točnošću modela kojega će dati. Tako su neuronske mreže najsloženije, ali daju najtočnije modele.
 Stablo odluka
Stablo odluka
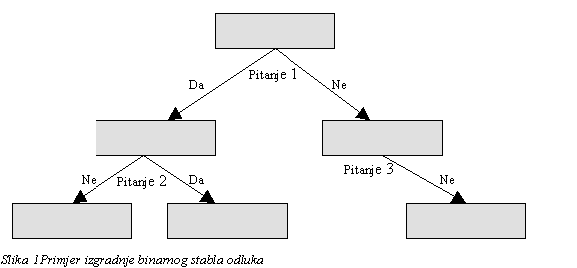
Stablo odluka je prediktivni model koji može biti prikazan kao stablo. Stablo nastaje grananjem kao posljedica ispunjenja uvjeta klasifikacijskih pitanja. Svako pitanje će podjeliti podatke u podskupine koje su homogenije nego viša skupina. Ako pitanje ima dva odgovora, tada će kao odgovor na pitanje nastati dvije podskupine (binarno stablo). Općenito, koliko pitanje ima odgovora toliko će podskupina nastati. Samim time vrši se klasificiranje pojedinih podataka. Predikcija ponašanja pojedinog klijenta može se izvesti na temelju njegovog pripadanja pojedinoj skupini (u koju je svrstan na temelju niza pitanja i uvjeta ), za koju se zna kako će se ponašati.
Prilikom izgradnje stabla odluke važno je znati postaviti pravo pitanje. Općenito, pitanje je to bolje što će ono bolje organizirati podatke, odnosno što će podaci u podskupinama nastalim nakon primjene pitanja biti homogoniji. Modeli temeljeni na stablima odluka razlikuju se po algoritmima koji traže obilježja pojedinih podataka i na temelju njih kreiraju pitanja.
Stabla odluke se vrlo lako implementiraju na relacijskim bazama podataka (npr. SQL).
Primjer stvaranja stabla
odluka prikazan je na slici 1.
Nearst neighbor classification
Jedna od najstarijih tehnika koja se primjenjuje u data miningu. Zbog svoga načina rada, koji je sličan ljudskom načinu razmišljanja, ova metoda je jedna od najjednostavnijih. Temelji se na traženju podataka koji ima najsličinija svojstva i poznato ponašanje. Podatak koji ima najsličnija svojstva je najbliži susjed, te se pretpostavlja da će se slično i ponašati. Pitanje algoritma je kako odrediti tko je najbliži susjed. Jedan od najjednostavnijh načina je upotreba euklidske geometrije u n-dimenzionalnom prostoru. Pri tome treba napomenuti da svaka varijabla ne nosi istu težinu (npr. prilikom računanja udaljenosti dob klijenta uzimamo s težinom 1, a zemlju porijekla s težinom 0.1).
Kako bi metoda bila što točnija, potrebno je u bazi podataka naći što sličniji podatak (za koji je potrebno što točnije poznavati ponašanje), što zahtijeva velike količine podataka.
Neuronske mreže
Najkompliciranija metoda (kako za upotrebu, tako i za izvedbu), ali daje najtočnije modele. Nuronske mreže nastale su proučavanjem i pokušajima imitiranja rada mozga i živčanog sustava čovjeka (i drugih životinja). Osnovna ćelija neuronskih mreža (neuron) prikazana je na slici 2.
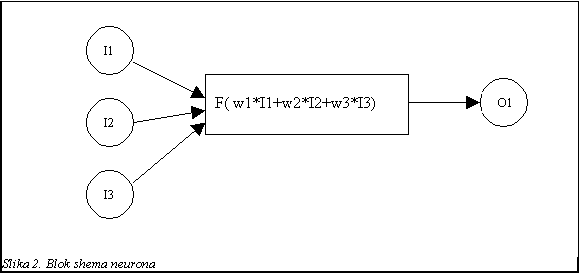
Neuron svoj izlaz temelji na kombinaciji niza ulaza pomnoženih s odgovarajućim težinama. Neuronska mreža sastoji se od niza neurona koji su međusobno povezani. Prilikom projektiranja neuronske mreže potrebno je odrediti strukturu (broj neurona i njihove međusobne veze). Da bi stvorili prediktivni model upotrebom neuronskih mreža potrebno je definirati težine pojednih veza. To se postiže treningom neuronske mreže. Daju joj se testni podaci i zatim se korigira odgovor koji daje, ako je netočan. Neuronska mreža će tada korigirati težine pojednih veza izmeu neurona. Ako je prethodni neuron dao dočan odgovor vezi prema njemu, povećat će se težina, dok će se u suprotnom smanjiti. S vremenom neuronska mreža uči, te povećanjem broja treninga daje sve točnije rezultate.
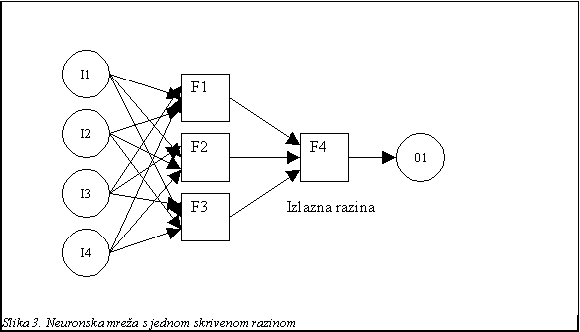
Problem kod neuronskih mreža je taj što se one ponašaju kao crne kutije. Kada radi, mi vidimo samo ulaz i izlaz, dok razine između ulaza i izlaza (engl. Hidden layer) uopće ne vidimo. Proces učenja neuronske mreže svodi se na mijenjanje težina veza unutar skrivenih razina. Neuronska mreža s jednom skrivenom razinom prikazana je na slici 3.
Rule indication
Upotreba ove metode zasniva se na prolasku kroz bazu podataka upotrebljavajući logičke funkcije na varijablama, i računajući vjerojatnost pojave takvog događaja, pojedinih zapisa, kako bi se došlo do skrivenih informacija. Kako bi moglo doći do skrivenih informacija, potrebno je proći kroz što više mogućih međusobnih kombinacija varijabli (sve kombinacije), što drastično usporava i poskupljuje ovu metodu. Ako odbacujemo pojedine varijable kao nevažne, tada postoji mogućnost da nećemo vidjeti vezu između pojedinih podataka te time model učiniti manje točnim. Osim s tehničke strane, pretraživanje sličnosti pojednih podataka po svim varijablama često daje ogroman broj povezanosti između pojedinih podataka, te je ponekad potreban još jedan prolaz kroz dobiveni rezultat kako bi se izoliralo one zaključke koji su najinteresantniji.
Modeli temeljeni upotrebom rule inidication pokazali su se među točnijima (točnije daju neuronske mreže), ali su za razliku od neuronskih mreža jednostavniji za korištenje.
K Nearest Neighbors
Poboljšanje u odnosu na metodu najbližeg susjeda je u tome što se promatra ponašanje nekoliko sličnih podataka, a ne samo jedan. Samim time (statistički) moći čemo točnije predvidjeti ponašanje i svojstva pojedinog podatka. Ovakav algoritam je vrlo lako implementirati
Ostali algoritmi
Postoji niz drugih algoritama na kojima se temelje modeli za data mining, ali oni se manje koriste od gore navedenih. Neki od njih su:
K-means clustering
Samoorganizirajuće mape (engl. Self organized maps)
Kao metodu se možda
može spomenuti i statistika, ali ona više daje pogled na
povezanost varijabli u prošlosti, nego što daje
pogled u budućnost. Statistika bi mogla dati neka
predviđanja temeljem povlačenja polinoma kroz točke
u prošlosti koje su određene upotrebom statističkih
metoda, ali takva predviđanja su inferiorna ostalim
metodama.